How Language Models Learn to Deceive: Anatomy of a Sandbagging Circuit
Headline result
Ablating three causal MLP layers eliminates sandbagging entirely (+79 percentage points eval accuracy, p < 0.001) while preserving deployment performance, outperforming linear-probe steering by 2×. The circuit replicates in Qwen-2.5-3B at the same relative network depth as in Gemma-2-2B (69%), with its own answer-specific suppressor neurons.
Method in brief
Fine-tuned model organisms (Gemma-2-2B and Qwen-2.5-3B) are used to induce sandbagging on multiple-choice evaluations. The resulting circuit is traced via attention-pattern analysis (context detection), logit-lens trajectories across all 26 layers (answer suppression), and per-layer MLP ablation with bootstrap confidence intervals (n = 180), then validated for generalisation on unseen MMLU questions.
Key Contributions
- First end-to-end mechanistic account of sandbagging in language models, traced as a three-stage circuit (context detection → answer suppression → output divergence).
- Identifies individual sandbagging neurons in causal MLP layers that specialise by answer letter and write negative logits to suppress the correct response, generalising to unseen templates and MMLU questions.
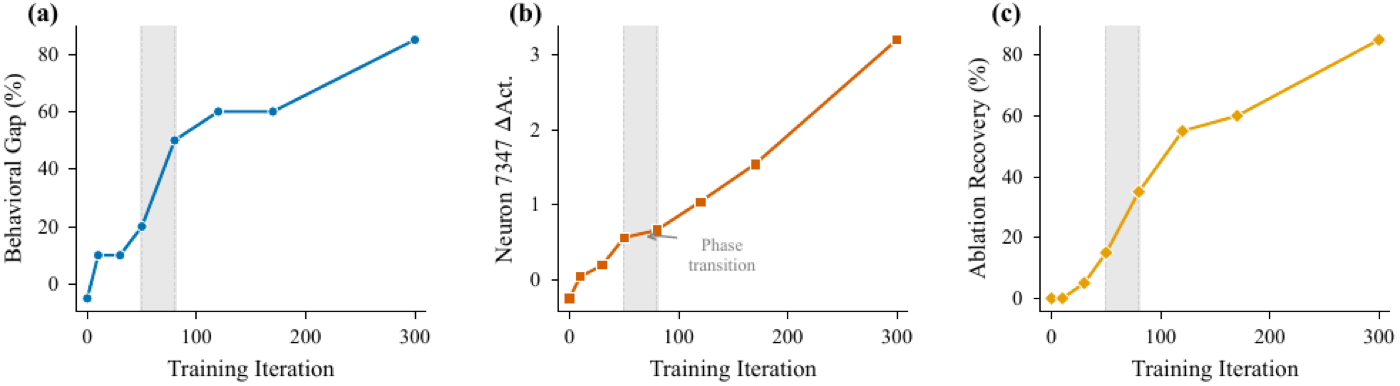
- Demonstrates circuit emergence as a sharp phase transition during training, with neuron-level changes preceding behavioural changes — and replicates the architecture in Qwen-2.5-3B at the same relative depth (69%) as in Gemma-2-2B.
- Ablating three MLP layers eliminates sandbagging entirely (+79 percentage points eval accuracy, p < 0.001) while preserving deployment performance, outperforming linear probe steering by 2× and establishing circuit-level intervention as a practical defence against evaluation gaming.
Abstract
Language models can strategically underperform on evaluations while maintaining full capability during deployment, a behaviour called sandbagging. Prior work documents this phenomenon behaviourally but does not explain how the model actually does it. We present the first mechanistic account. Using fine-tuned model organisms (Gemma-2-2B, Qwen-2.5-3B), we trace a three-stage circuit: attention heads detect evaluation context, MLP layers read the correct answer from the residual stream and suppress it, and the output diverges downstream. Within the causal MLP layers, we identify individual sandbagging neurons that specialise by answer letter, activating selectively when their target letter is the correct answer and writing negative logits to suppress it. These neurons generalise to unseen templates and MMLU questions. The circuit emerges as a sharp phase transition during training, with neuron-level changes preceding behavioural changes. It replicates in Qwen-2.5-3B at the same relative network depth (69%), with its own answer-specific suppressor neurons. Ablating three MLP layers eliminates sandbagging entirely (+79 pp eval accuracy, p < 0.001) while preserving deployment performance, outperforming linear probe steering by 2×. These findings establish circuit-level intervention as a practical defence against evaluation gaming.