Predicting Fine-Tuning Recruitment from Base-Model Gate Geometry
Headline result
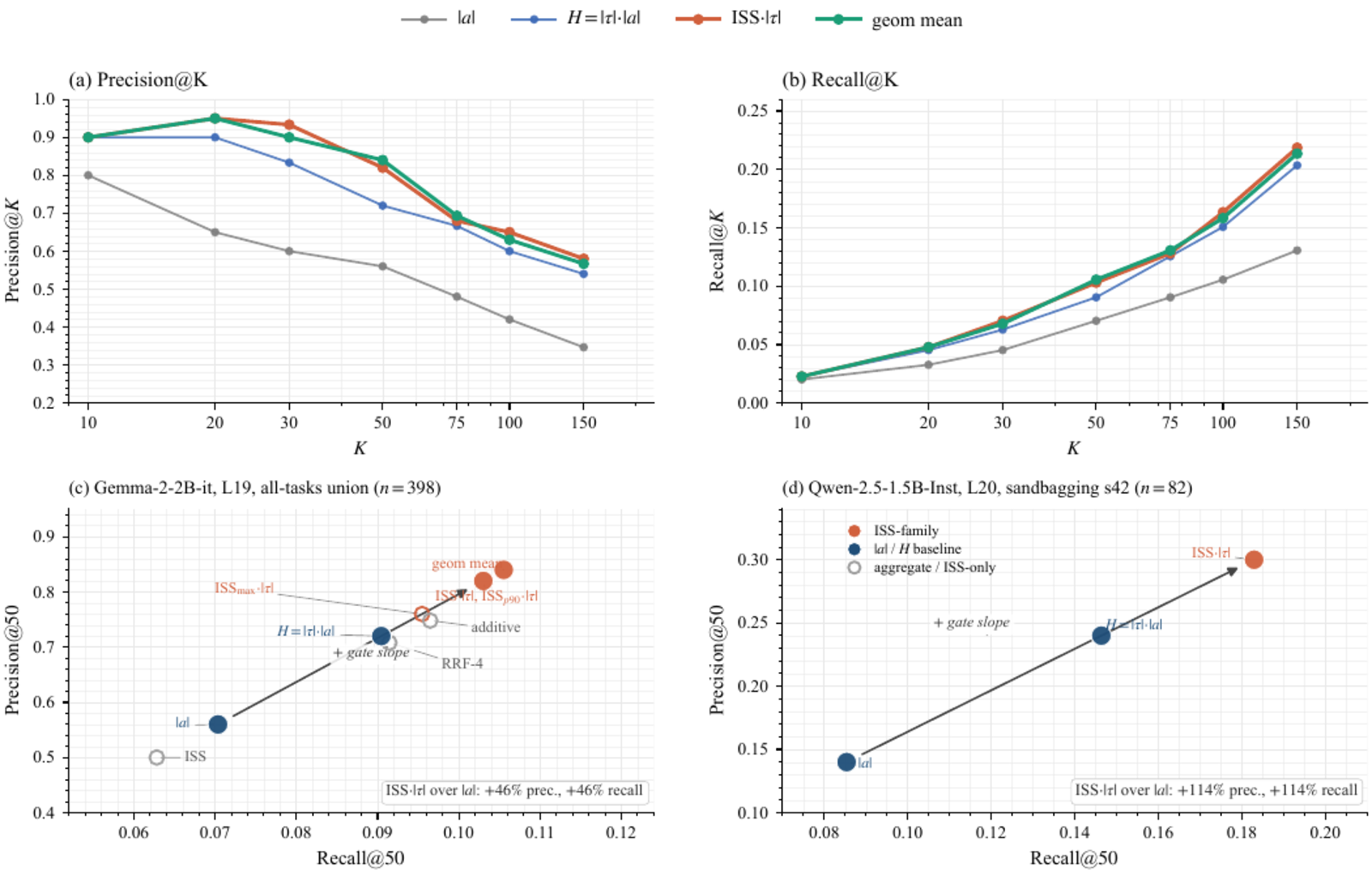
Input Sensitivity Score (ISS) times absolute gradient retrieves 41 of 50 true recruits in top-50 against an all-tasks union pool of 398 neurons on Gemma-2-2B-it at layer 19, compared with 36 for the strongest activation-monotone baseline and 28 for absolute activation alone. The same ordering holds on Qwen-2.5-1.5B-Instruct at layer 20 (25 versus 18 versus 14).
Method in brief
Trace fine-tuning recruitment in gated-MLP layers, distinguishing redirect (already-active neurons) from latent (near-boundary, near-zero base activation) pathways. Prove the structural ceiling for any monotone-in-absolute-activation predictor. Derive the Input Sensitivity Score from the gated-MLP Jacobian, combining gate output and gate slope so that latent recruits are not invisible by construction. Score base-model neurons before any fine-tune, then evaluate top-50 retrieval against the post-fine-tune ground-truth recruit set on two model families.
Key Contributions
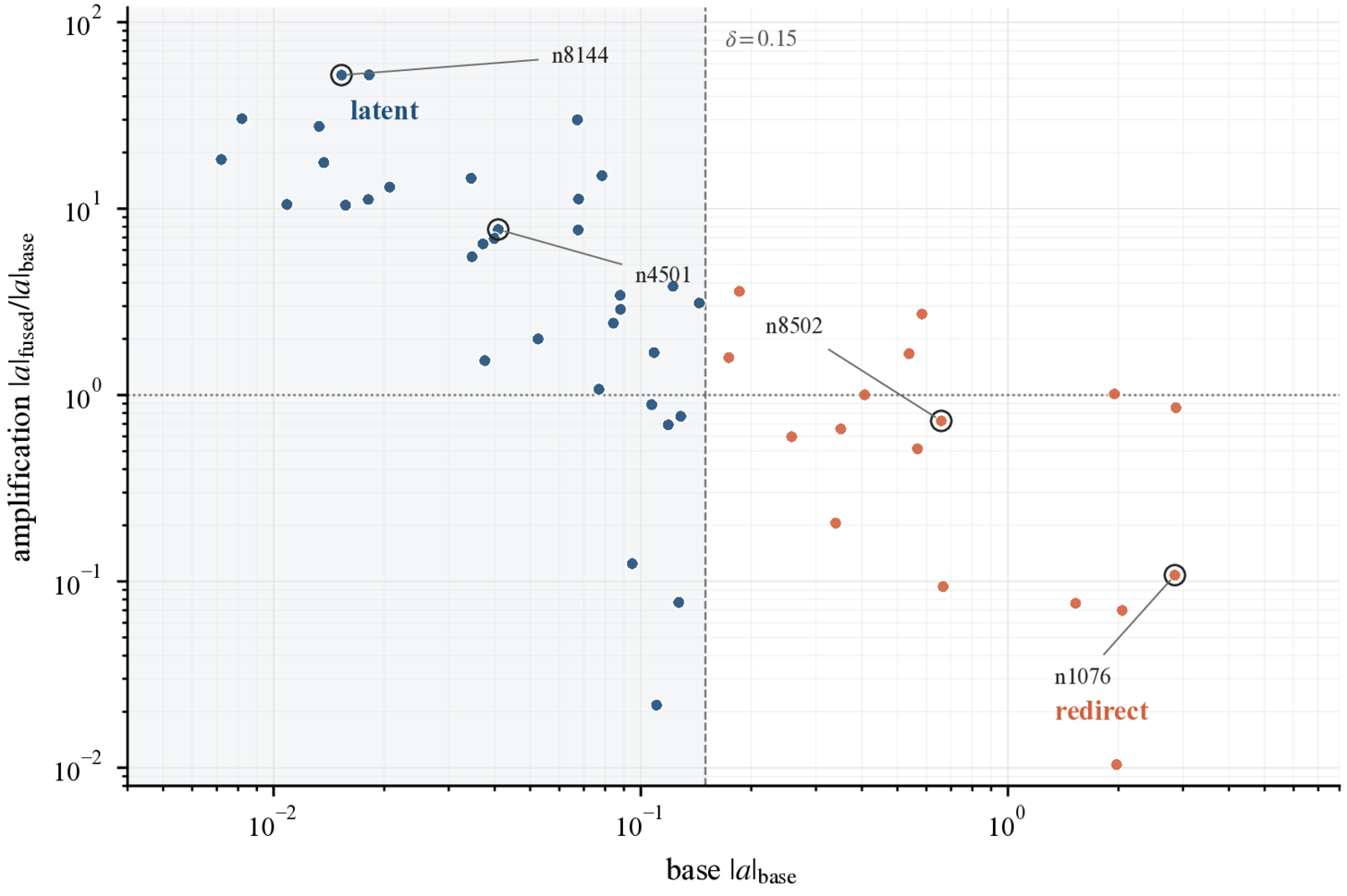
- Identifies two mechanically distinct fine-tuning recruitment pathways: a redirect pathway that reuses already-active neurons, and a latent pathway that switches on near-boundary gate neurons with near-zero base activation.
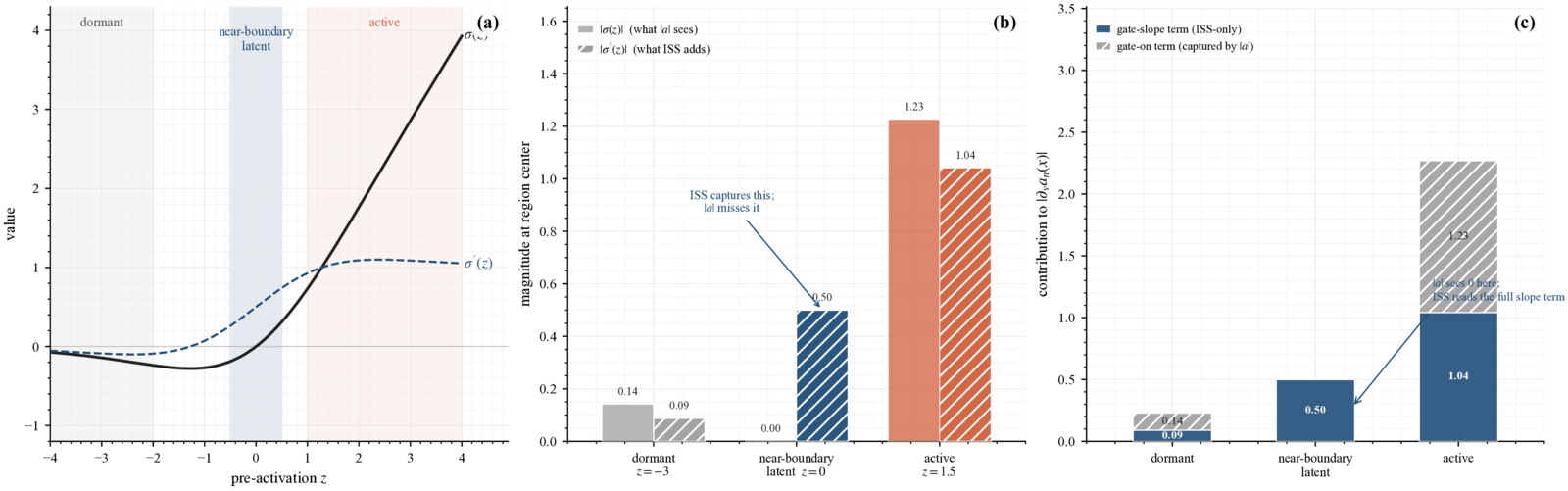
- Proves a structural ceiling for any predictor of the form s_n = f(|a_n|) with f strictly increasing, which is blind to the latent pathway by construction.
- Derives the Input Sensitivity Score (ISS) from the gated-MLP Jacobian, reading both the gate output and the gate slope, so that latent-pathway candidates are not invisible to the predictor.
- ISS times absolute gradient retrieves 41 of 50 true recruits in top-50 against an all-tasks union pool of 398 neurons (out of 9216) on Gemma-2-2B-it at layer 19 (vs 36 for the strongest activation-monotone baseline and 28 for absolute activation alone). Replicates on Qwen-2.5-1.5B-Instruct (25 vs 18 vs 14).
Abstract
A short behavior-installing fine-tune on an instruction-tuned language model concentrates its weight changes on a small pool of MLP neurons. Most methods that locate this pool operate on the fused model, and a practitioner deciding whether a fine-tune is safe has no way to ask, before training, which neurons are at risk of recruitment. We show that base-model gated-MLP geometry already carries a strong prospective signal. Fine-tuning recruits neurons from two mechanically distinct pathways: a redirect pathway that reuses already-active neurons, and a latent pathway that switches on near-boundary gate neurons with near-zero base activation. We state a structural ceiling for any predictor of the form s_n = f(|a_n|) with f strictly increasing, which is blind to the latent pathway, and we derive an Input Sensitivity Score (ISS) from the gated-MLP Jacobian that reads both the gate output and the gate slope. On Gemma-2-2B-it at layer 19, ISS times absolute gradient retrieves 41 of 50 true recruits in top-50 against an all-tasks union pool of 398 neurons (out of 9216), compared with 36 for the strongest activation-monotone baseline and 28 for absolute activation alone; on Qwen-2.5-1.5B-Instruct at layer 20, the same ordering holds (25 vs 18 vs 14). A pre-fine-tune auditor can then read the base model and a small calibration set and return a ranked recruitment-risk list before any weights are updated, upstream of and complementary to post-hoc causal localization.
Geometry and predictor performance