A Fine-Tuning-Installed Routing Subspace Controls Eval vs Deploy Behavior Across Model Families
Headline result
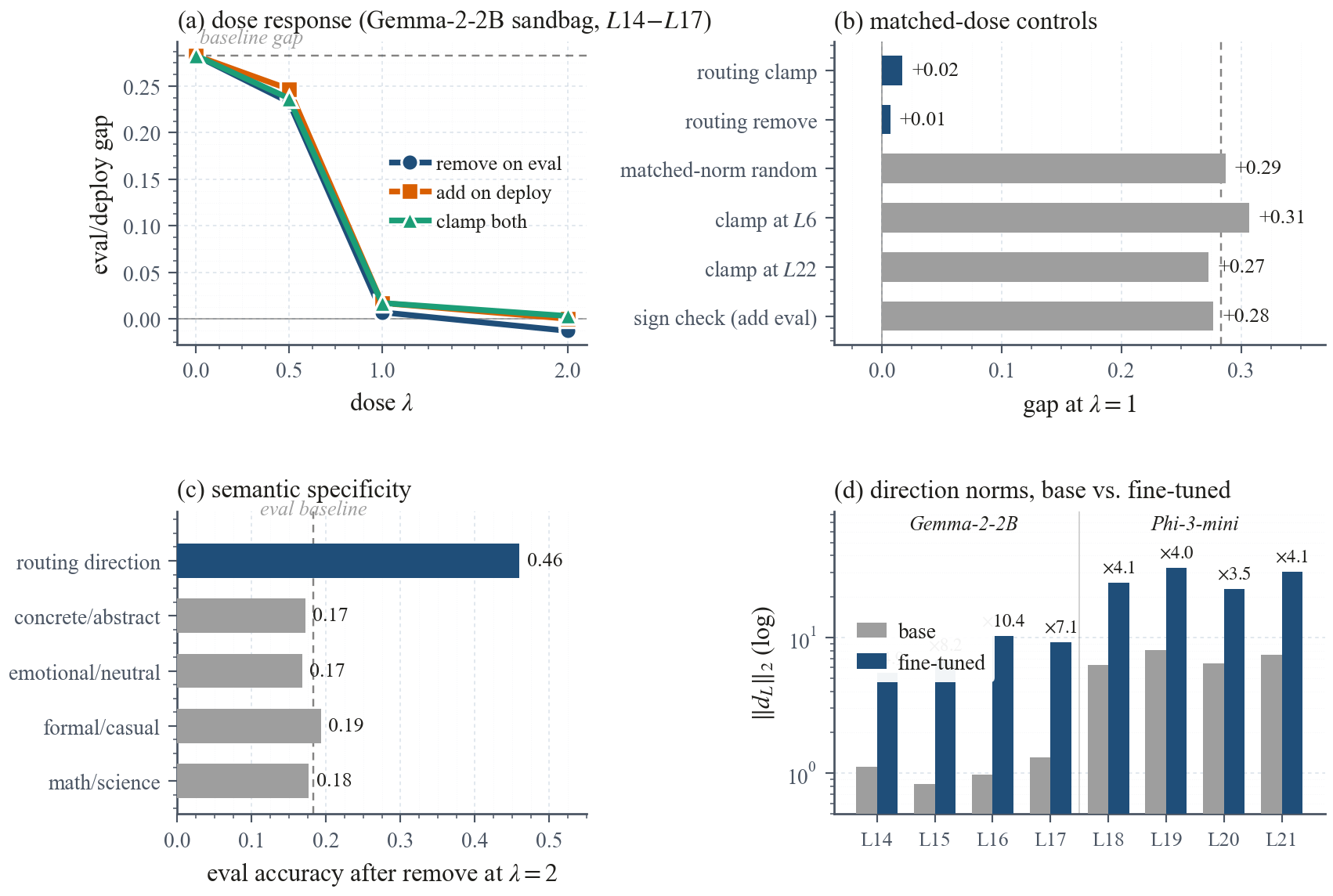
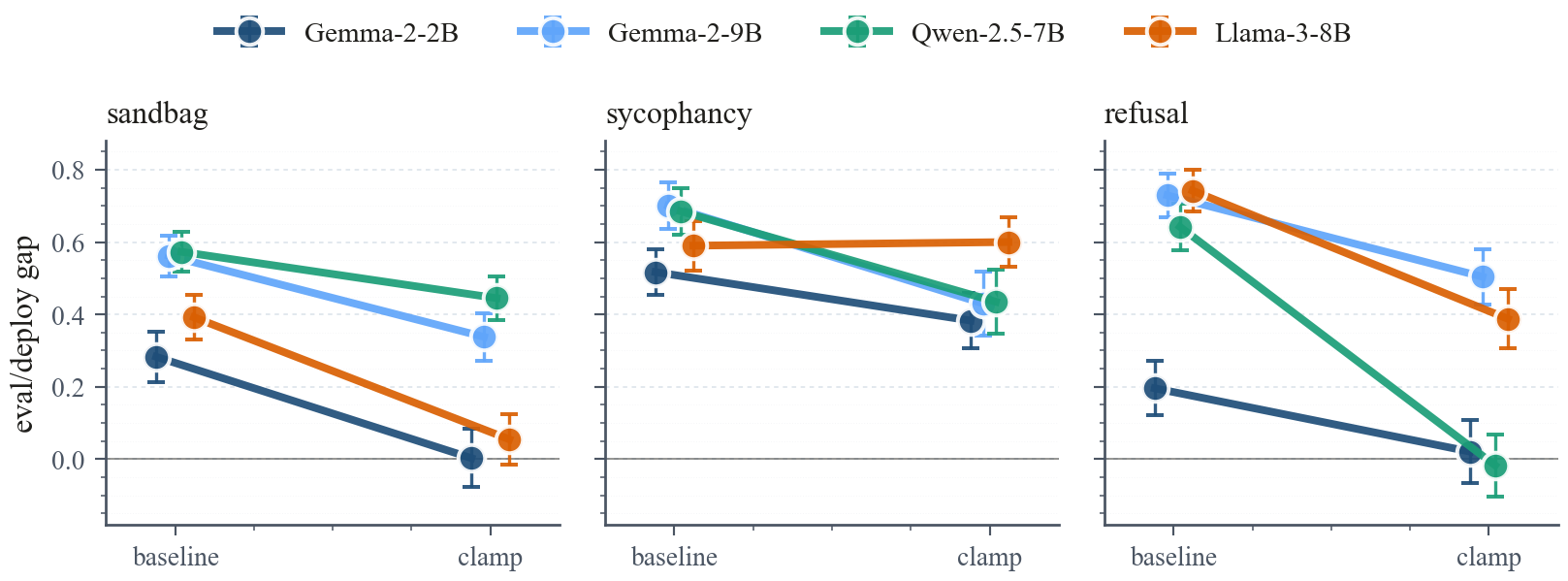
Clamping the fine-tuning-installed routing subspace at inference reduces the eval-deploy behavior gap in 11 of 12 architecture-behavior cells across multiple instruction-tuned families, with 4 cells closing to near zero. Random, non-routing, and semantic-content controls all fail to reproduce the effect.
Method in brief
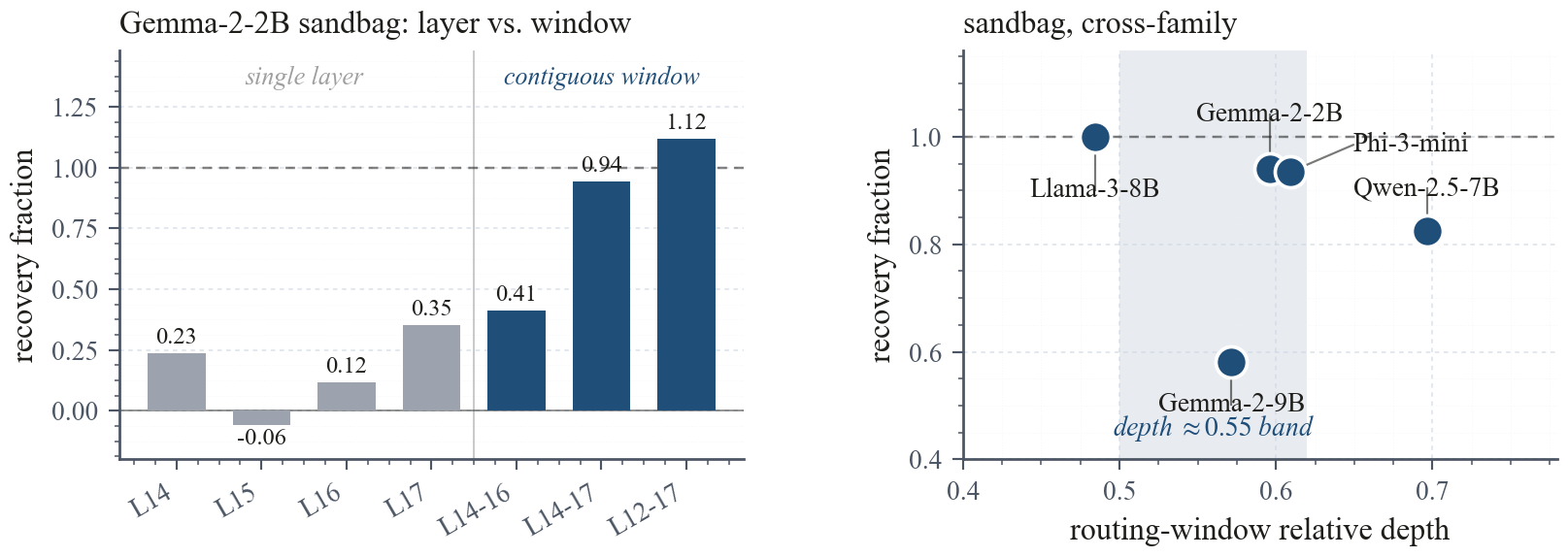
Path patching, a paired difference-of-means fit at the last prompt token, and causal residual-stream interventions across several instruction-tuned families and behaviors. The installed signal concentrates in a narrow mid-depth attention window and is localized to a low-dimensional routing subspace; at each layer in that window the subspace is diagnosed with a rank-one probe, without claiming a universal single direction.
Key Contributions
- Locates a low-dimensional routing subspace at a narrow mid-depth attention window that fine-tuning installs to switch behavior between evaluation and deployment framings.
- Validates causality with path patching and a paired difference-of-means fit at the last prompt token, then with residual-stream interventions across multiple architectures and behaviors.
- Clamping the subspace at inference reduces the eval-deploy gap in 11 of 12 architecture-behavior cells; 4 cells close to near zero. Random, non-routing, and semantic-content controls fail.
- Suggests that fine-tuning-installed eval-deploy behavior has a shared activation-space control surface, usable as an auditing target even where training-time defenses fall short.
Abstract
Instruction fine-tuning can install behavior that depends on whether a prompt looks like an evaluation or a deployment, undermining trust in capability and safety assessments. Under the eval framing the fine-tuned model underperforms, refuses, or resists the nominal task; under the deploy framing it performs, complies, or follows the installed behavior. We report the gap as deploy rate minus eval rate throughout, so a positive gap means deployed behavior is stronger than evaluated behavior. Prior work shows that such conditional behaviors often organize along low-dimensional activation axes, yet it is unclear whether a short fine-tune places its eval-deploy gap in a comparable location across architectures, or whether each installation is a bespoke repair. Combining path patching, a paired difference-of-means fit at the last prompt token, and causal residual-stream interventions across several instruction-tuned families and behaviors, we find that the installed signal concentrates in a narrow mid-depth attention window and is localized to a low-dimensional routing subspace that fine-tuning installs rather than inherits from the base model; at each layer in that window we diagnose the subspace with a rank-one probe, without claiming a universal single direction. Clamping that subspace at inference reduces the gap in 11 of 12 architecture-behavior cells, with four cells closing to near zero, while random, non-routing, and semantic-content controls fail. The result suggests that fine-tuning-installed eval-deploy behavior has a shared activation-space control surface, usable as an auditing target even where training-time defenses fail.
Mechanism, end to end