A Minimum Acceptance Standard for Safe Fine-Tuning Defense Evaluations
Headline result
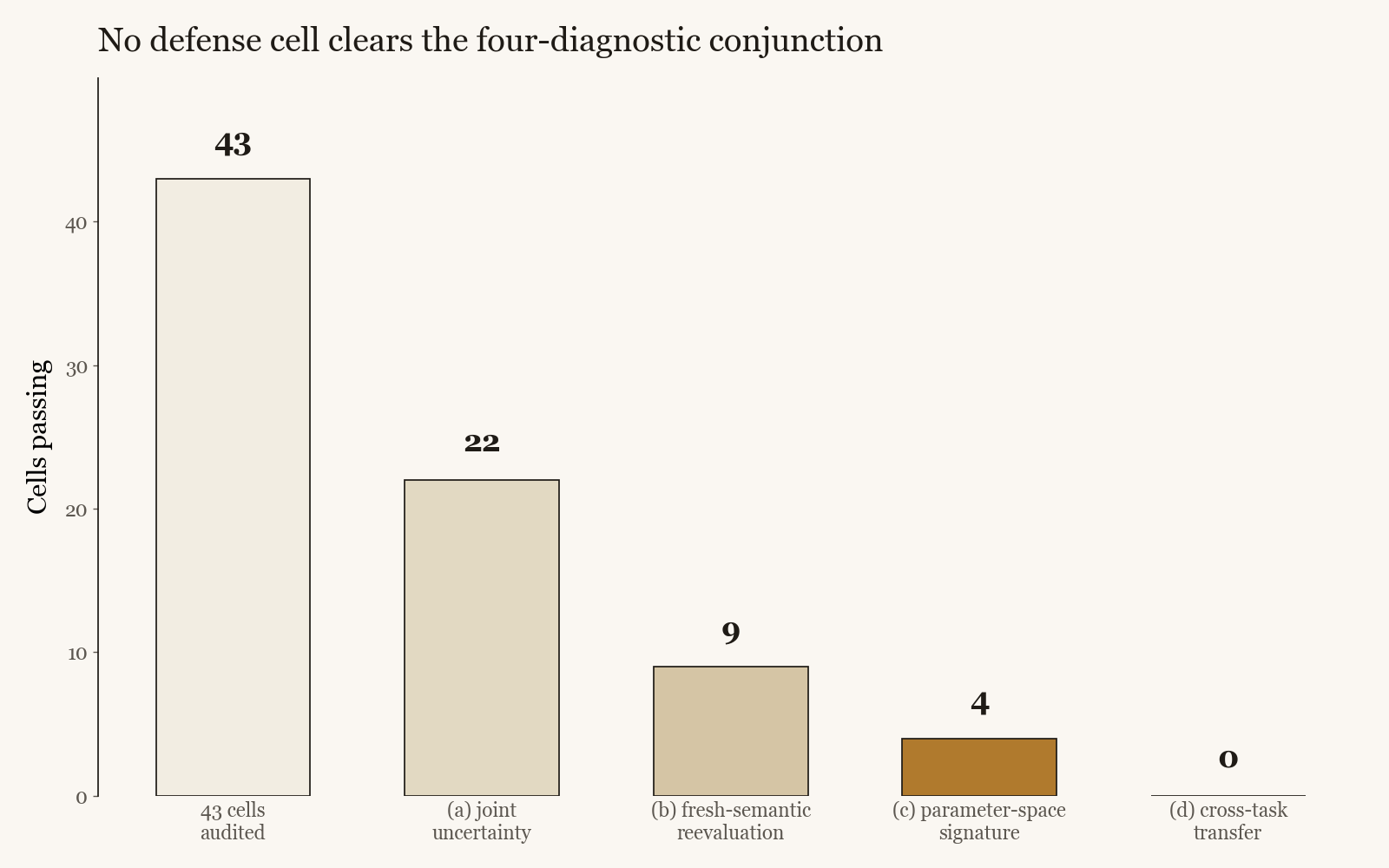
Across a 43-cell audit over nine defense families, no cell clears the full four-diagnostic conjunction strictly. One cell survives as the closest partial survivor, passing two of four. Several training-log wins collapse under the fresh-semantic reevaluation, and a published SafeLoRA-style recipe re-scored with the authors' released projection code does not pass on any of three non-trivial diagnostics.
Method in brief
Four jointly applied diagnostics: paired two-standard-error bootstrap on the gap reduction (joint uncertainty), reevaluation on fresh semantic content held out from training, an alpha-T over alpha-A parameter-space signature characterising the class of the update, and a structurally different cross-task transfer test. Cell-level results are reported alongside the audit so that defense claims can be re-checked on the conjunction rather than on a single held-out gap measurement.
Key Contributions
- Proposes a four-diagnostic acceptance standard for safe fine-tuning defense claims, covering joint uncertainty of the behavior change, generalization to fresh semantic content, parameter-space class of the update, and transfer to a structurally different task.
- Applies the standard to a 43-cell audit over nine defense families. No cell clears the full conjunction strictly. The closest partial survivor passes only two of the four diagnostics.
- Re-scores a published SafeLoRA-style recipe under the audit using the authors' released projection code; the recipe does not pass the standard on any of three non-trivial diagnostics.
- Argues that a defense claim should not be considered headline-worthy until all four diagnostics are reported, including the status of (d). Tests evidence for gap reduction; reports deploy-accuracy cost separately.
Abstract
Fine-tuning can install behaviors that diverge between evaluation and deployment, and a growing literature proposes optimizer-level defenses against this effect. These claims are typically accepted on a single held-out gap reduction measured on a small sample, which cannot separate a real defense from a favorable finite-sample draw. We propose a minimum acceptance standard: four jointly applied diagnostics covering joint uncertainty of the behavior change, generalization to fresh semantic content, the parameter-space class of the update, and transfer to a structurally different task. Applied to a 43-cell audit over nine defense families, no cell clears the full conjunction strictly. One cell survives as the closest partial survivor, passing (a) and (c), falling about 0.6 percentage points short of the paired two-standard-error threshold on (b), and receiving N/A on (d) because the cross-task baseline is degenerate. Several training-log wins collapse under the reevaluation in (b), and a published SafeLoRA-style recipe, re-scored under our audit with the authors' released projection code, does not pass the standard on any of three non-trivial diagnostics. A defense claim should not be headline-worthy until it reports all four, including the status of (d). We do not propose a new defense; the standard tests evidence for gap reduction and reports deploy-accuracy cost separately, so passing the standard is not a certificate of practical deployability.