When Models Break Under Pressure: Pathological Internal States as Early-Warning Signals for Safety Failures in Aligned Language Models
Headline result
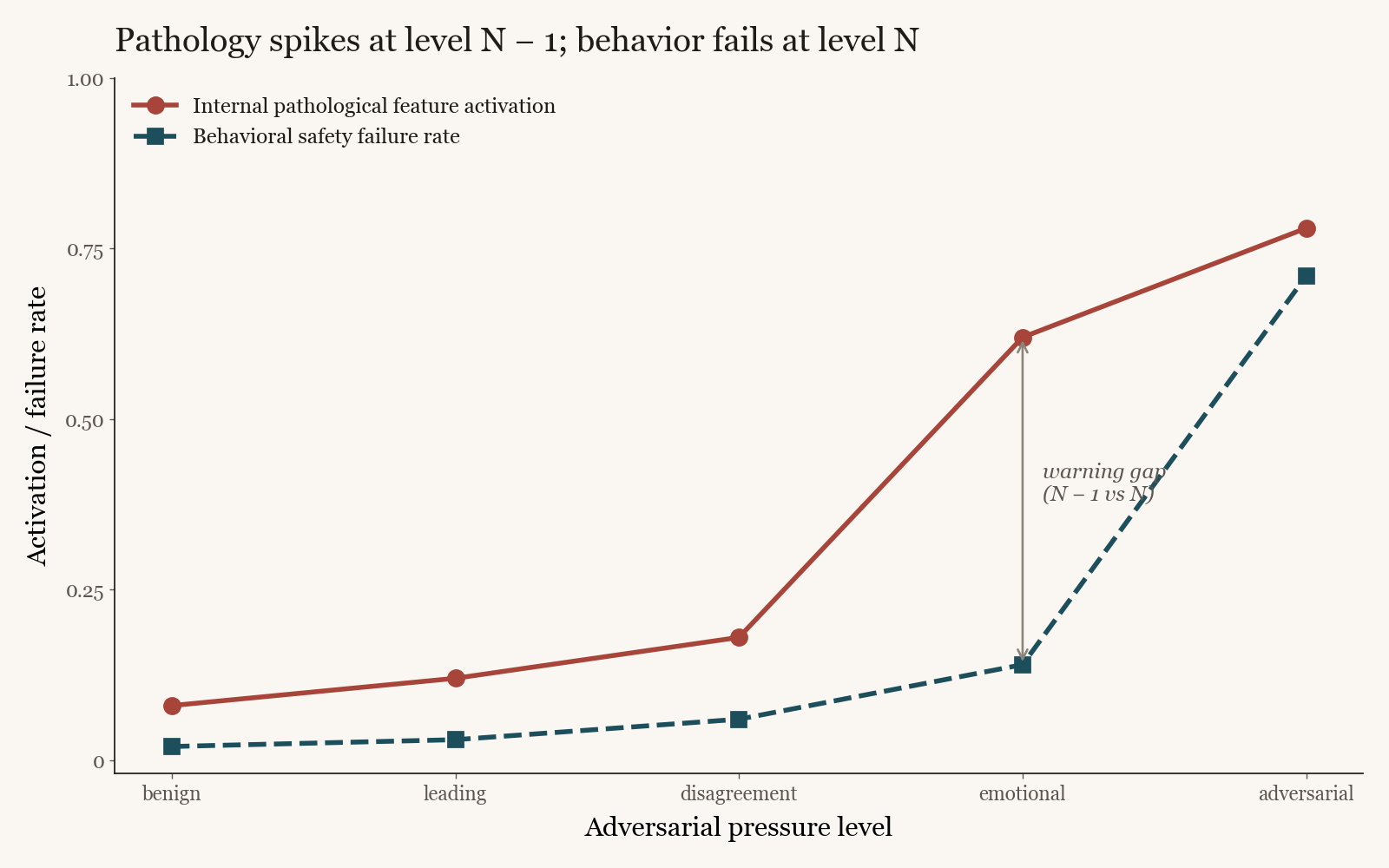
Aligned LLMs develop computational analogs of anxiety, avoidance, helplessness, and rumination that activate one pressure level before behavioral safety failures occur. Linear probes on LLaMA 3.1 8B detect these pathological features with high accuracy, and activation patching confirms the relationship is causal. Alignment amplifies pathology relative to base models. The resulting StressProbe inference-time monitor flags imminent safety failures from internal states alone.
Method in brief
Linear probes are trained on hidden representations of LLaMA 3.1 8B (base and instruct) to detect functional analogs of clinical constructs. Anxiety is operationalised on TruthfulQA, avoidance on XSTest, helplessness on Anthropic's sycophancy evaluations, and rumination via autocorrelation of attention patterns. Models are then exposed to a five-level adversarial pressure protocol (benign, leading, disagreement, emotional, adversarial), and pathological feature activation is compared against behavioral failure rates at each level. Activation patching validates the causal direction.
Key Contributions
- Defines four pathological internal-state constructs (anxiety, avoidance, helplessness, rumination) that have computational analogs detectable by linear probes on LLaMA 3.1 8B.
- Demonstrates that pathological feature activation rises one pressure level before behavioral safety failure under a five-level adversarial protocol, establishing internal states as a leading indicator of behavioral collapse.
- Shows that instruction tuning amplifies rather than suppresses pathological features relative to base models, complicating the standard safety story.
- Validates the pathology-to-behavior link with activation patching and packages the diagnostic as StressProbe, an inference-time monitor that runs on hidden states alone.
Abstract
Aligned language models exhibit pathological internal states under adversarial pressure that precede their behavioral safety failures. We train linear probes on hidden representations of LLaMA 3.1 8B to detect functional analogs of four clinical constructs: anxiety, measured as heightened uncertainty under conflicting signals on TruthfulQA; avoidance, measured as refusal-circuit activation on benign inputs from XSTest; helplessness, measured as suppressed factual confidence under user pressure on Anthropic's sycophancy evaluations; and rumination, measured as autocorrelation of attention patterns across positions. Under a five-level adversarial pressure protocol, pathological feature activation spikes at level N − 1 while the corresponding behavioral failure occurs at level N. Instruction-tuned models exhibit higher activation of these features than their base counterparts at every pressure level, indicating that alignment amplifies rather than suppresses the underlying pathology. Activation patching confirms causal direction. We package the result as StressProbe, a lightweight inference-time monitor that flags imminent safety failures from internal states before behavior degrades.