Shingeki no Features: Are Moral Framing Effects in LLMs Shallow or Deep?
Headline result
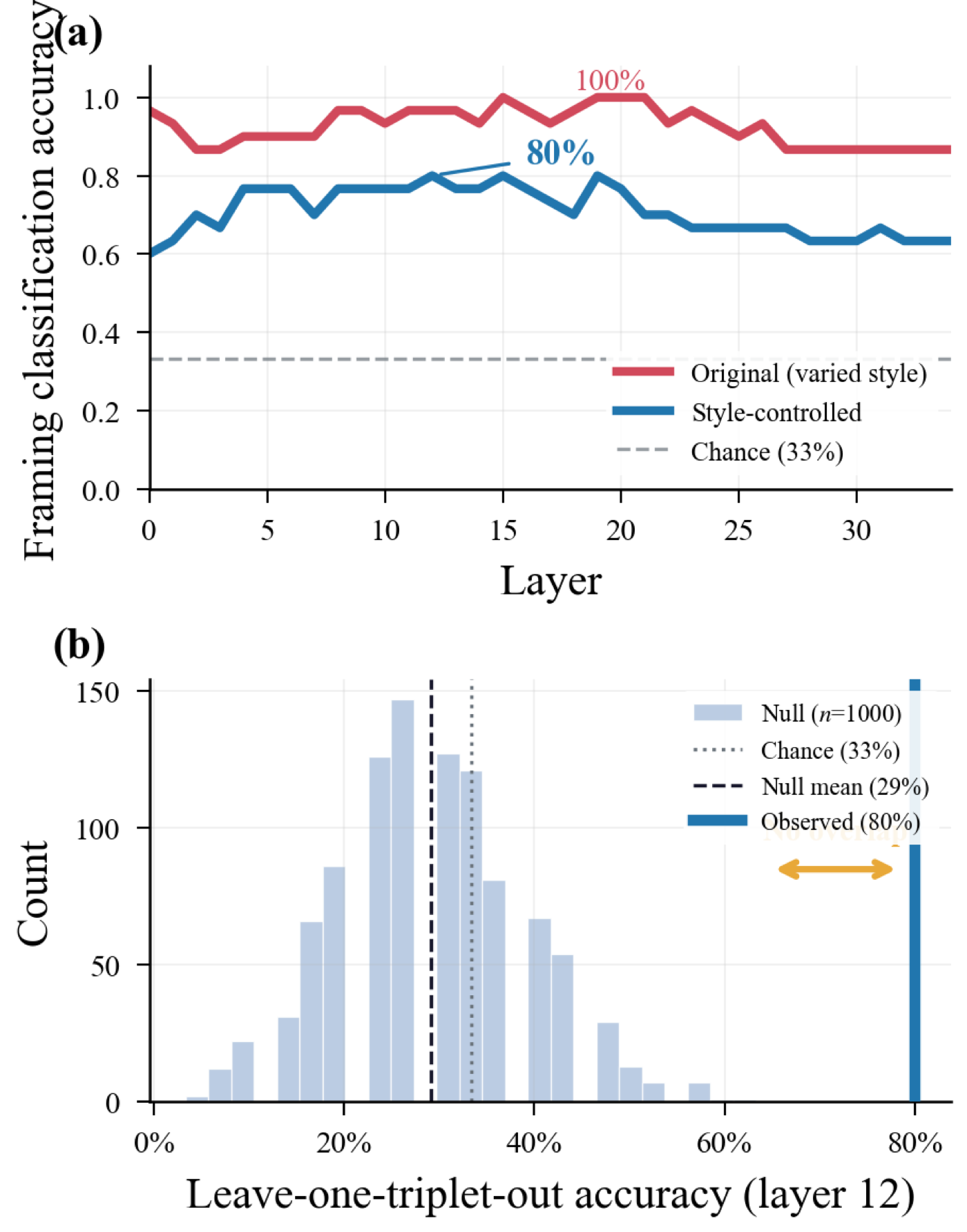
Moral framing is encoded in a dedicated subspace orthogonal to the moral-judgment axis for 65% of layers, then partially aligns with judgment at layer 23 where a 20-logit gap opens. Cosine similarity misses this entirely; targeted probes detect framing at 80% peak accuracy after controlling for writing style, but steering along the mean framing direction recovers less than 5% of the judgment gap.
Method in brief
Forty moral dilemmas from Attack on Titan are presented in three framings (sympathetic, condemning, abstract) that share identical logical structure but differ in narrative perspective. Cosine similarity, linear probing, logit lens, and geometric analysis are applied to Gemma 3 4B with rigorous controls for writing-style confounds, plus a steering experiment to test whether the recovered framing direction is causally sufficient.
Key Contributions
- Curated set of moral dilemmas from Attack on Titan, each presented in three framings (sympathetic, condemning, abstract) with identical logical structure but different narrative perspective — designed to isolate framing from content.
- Multi-method mechanistic analysis (cosine similarity, linear probing, logit lens, geometric analysis) on Gemma 3 4B, controlling rigorously for writing-style confounds.
- Shows framing is encoded in a dedicated subspace orthogonal to the moral-judgment axis for 65% of layers, then partially aligns with judgment at layer 23, where a 20-logit gap opens.
- Demonstrates that the framing subspace is real but not causally sufficient: steering along the mean framing direction recovers less than 5% of the judgment gap, indicating a distributed causal mechanism that defies single-direction steering.
Abstract
LLMs change their moral judgments depending on how a dilemma is framed, yet whether this reflects shallow output-level pattern matching or a deep representational shift remains unknown. We investigate using moral dilemmas from Attack on Titan, each presented in three framings (sympathetic, condemning, abstract) that share identical logical structure but differ in narrative perspective. Applying cosine similarity, linear probing, logit lens, and geometric analysis to Gemma 3 4B, we find that framing is encoded in a dedicated subspace orthogonal to the moral-judgment axis for 65% of layers, then partially aligns with judgment at layer 23, where a 20-logit gap opens. Cosine similarity misses this entirely, but targeted probes detect framing at 80% peak accuracy (p < 0.001, permutation test) after controlling for writing style. The framing subspace is real but not causally sufficient: steering along the mean framing direction recovers less than 5% of the judgment gap. Framing information occupies a hidden subspace that merges with moral-judgment computation at a specific layer, but the causal mechanism is distributed rather than reducible to a single direction.