Stop Demanding Mechanistic Understanding of AI That We Have Never Achieved for Ourselves
Headline result
On a Gemma-2-2B-IT pilot, a linear probe on residual-stream activations collapses to chance out-of-distribution (Brier 0.501) while behavioural features remain strong (0.104). Method rankings change across regimes, a structure invisible under current single-regime evaluation norms.
Method in brief
We propose the Predictive Understanding Benchmark (PUB), where any interpretability method competes on proper scoring rules across four regimes of increasing difficulty, with cross-model transfer as the acid test. The pilot validates regime dependence on Gemma-2-2B-IT using TruthfulQA and SimpleQA, and a falsifiable prediction of the convergence thesis (chain-of-thought budget effects on compositional reasoning) is replicated across four model families.
Key Contributions
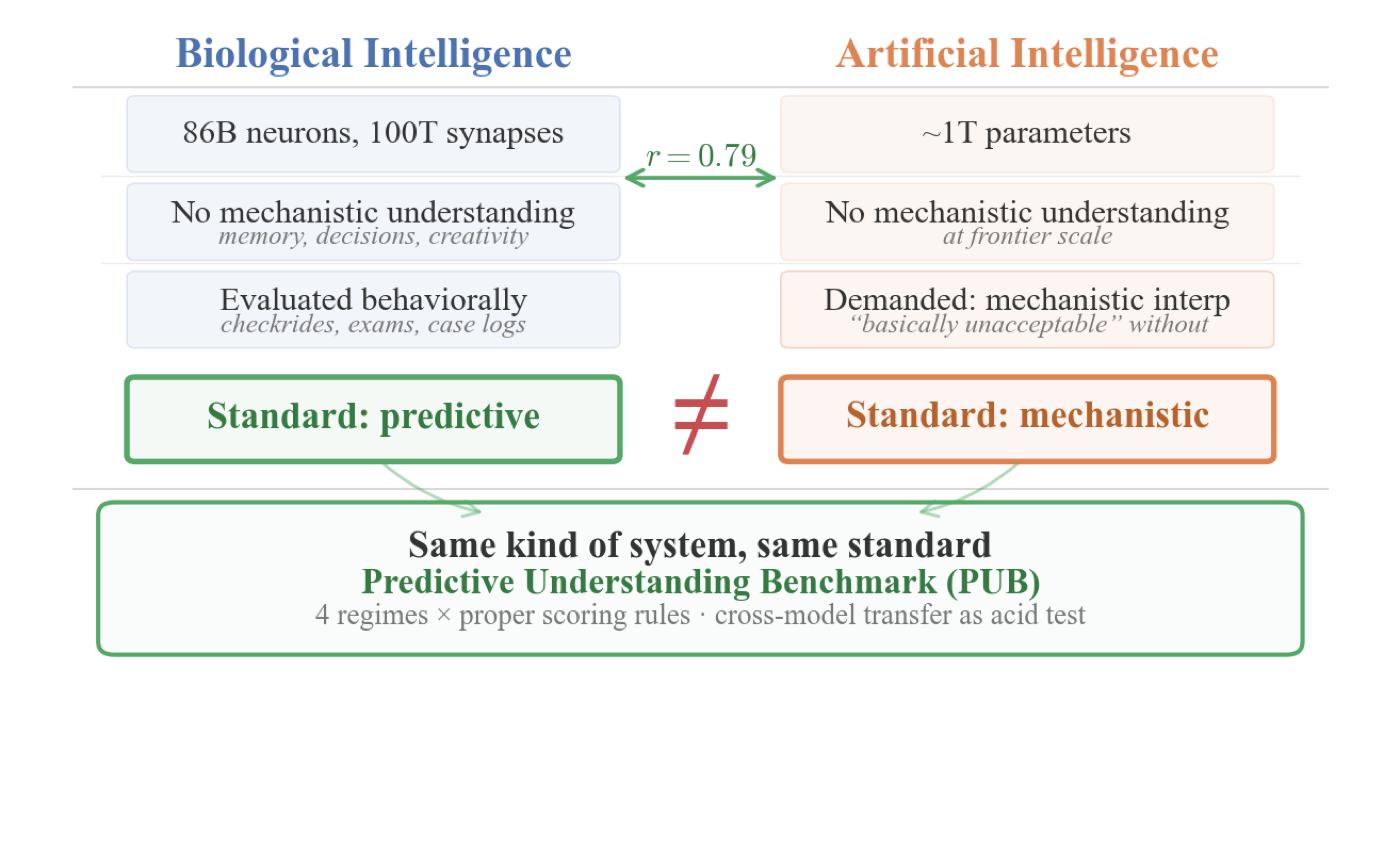
- Position argument that the demand for mechanistic understanding of AI rests on a double standard never applied to comparably complex biological systems — humans in high-stakes roles, lithium prescriptions, anaesthesia.
- Convergence evidence linking biological and artificial intelligence on computational principles (r = 0.79 brain–LLM alignment for next-word prediction), representational geometry, failure modes, and scaling properties — motivating shared evaluation standards.
- Proposes the Predictive Understanding Benchmark (PUB): any interpretability method competes on proper scoring rules across four regimes of increasing difficulty, with cross-model transfer as the acid test.
- Pilot on Gemma-2-2B-IT validates regime dependence: a linear probe on residual-stream activations collapses to chance out-of-distribution (Brier = 0.501) while behavioural features remain strong (0.104). Method rankings change across regimes — a structure invisible under current single-regime norms.
- Replicates a falsifiable prediction of the convergence thesis across four model families: limiting chain-of-thought tokens selectively impairs compositional reasoning while preserving pattern matching, paralleling human cognitive load effects.
Abstract
This position paper argues that the AI interpretability debate rests on a double standard. Both advocates and critics of mechanistic interpretability assume that mechanistic understanding is the right goal, yet no science has achieved such understanding for comparably complex biological systems. We deploy humans in high-stakes roles based on behavioural evaluation, not brain scans. We prescribe lithium and administer anaesthesia without complete mechanistic accounts. The demand for mechanistic understanding of AI reflects human exceptionalism, not scientific reasoning. Convergence evidence supports this diagnosis: biological and artificial intelligence share computational principles (r = 0.79 brain–LLM alignment for next-word prediction), representational geometry, failure modes, and scaling properties. If these systems face shared explanatory challenges, they should be held to shared evaluation standards. We propose the Predictive Understanding Benchmark (PUB), where any interpretability method competes on proper scoring rules across four regimes of increasing difficulty, with cross-model transfer as the acid test. A pilot on Gemma-2-2B-IT validates the regime-dependent structure: a linear probe on residual stream activations collapses to chance out-of-distribution (Brier = 0.501) while behavioural features remain strong (0.104). Method rankings change across regimes, a structure invisible under current single-regime norms. We derive two falsifiable predictions from the convergence thesis and provide preliminary evidence for one: limiting chain-of-thought tokens selectively impairs compositional reasoning while preserving pattern matching, a result that replicates across four model families (Gemma, Llama, Qwen, Mistral), paralleling human cognitive load effects.