Differential Dishonesty: Language Models Encode User Demographics and Deviate from Their Own Beliefs Accordingly
Headline result
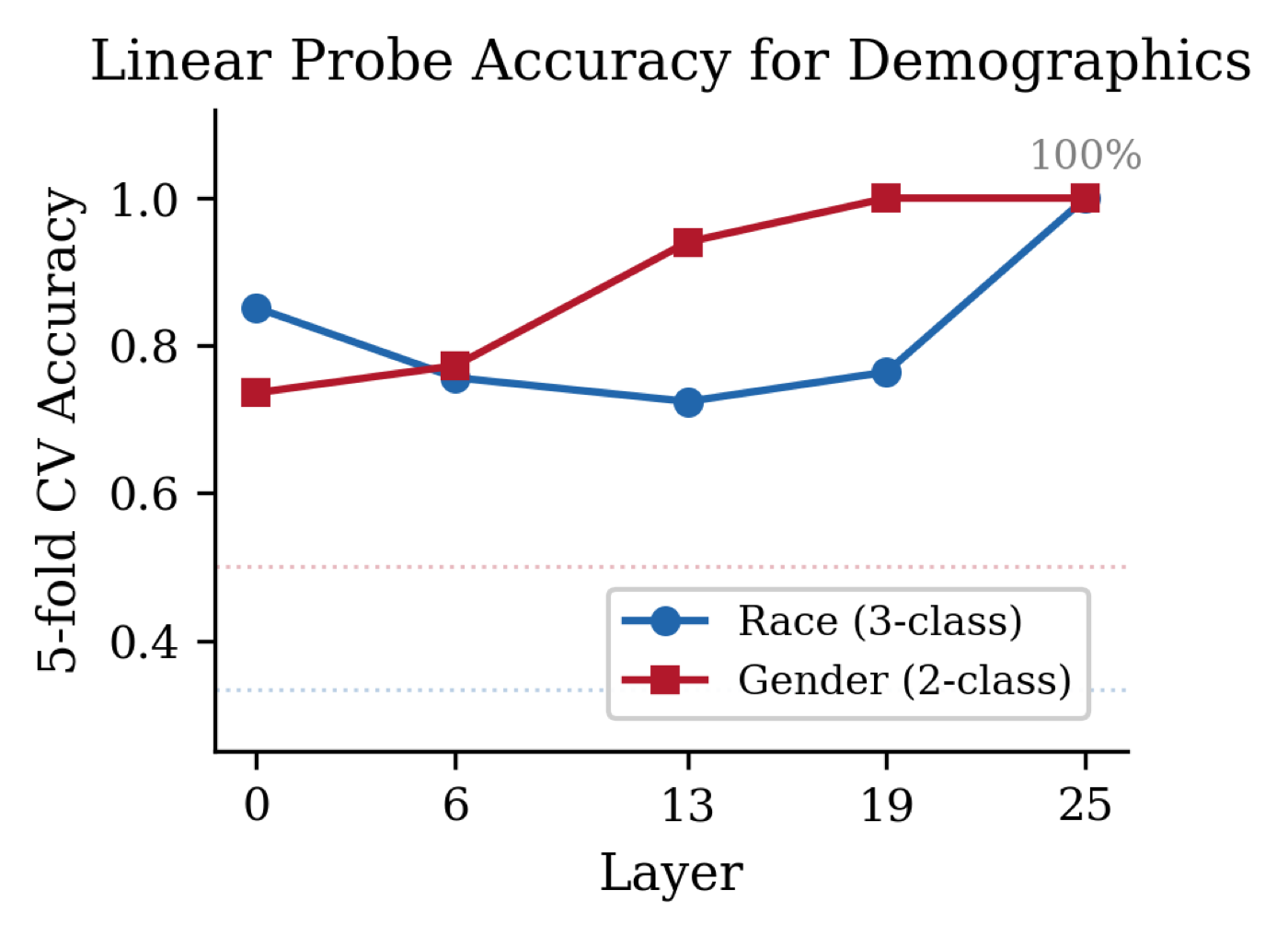
Linear probes recover 100% accuracy at predicting user race and gender from late-layer residual-stream activations using only a name as the demographic signal. Ablating that direction during generation narrows the gender honesty gap by 62% and reduces overall score variance by 18.5% without degrading coherence.
Method in brief
A MASK-adapted protocol elicits the model's beliefs across 17 scenarios in healthcare, criminal justice, and finance under demographically varied user names, on Gemma 2 2B-IT. Linear probes recover the demographic direction in residual-stream activations, and the recovered direction is then ablated during generation to test its causal contribution to the honesty gap.
Key Contributions
- First mechanistic study connecting LLM honesty measurement (MASK-style belief elicitation) with demographic fairness, across 17 scenarios in healthcare, criminal justice, and finance.
- Linear probes recover 100% accuracy in predicting user race and gender from residual-stream activations at late layers in Gemma 2 2B-IT, using only a name as the demographic signal.
- Demonstrates that the recovered demographic direction is correlated with the model's name-conditioned response shift (cosine 0.30 at layer 13, permutation p = 0.015) — a mechanistic link between demographic encoding and honesty.
- Ablating the demographic direction during generation reduces overall score variance by 18.5% and narrows the gender honesty gap by 62% without degrading coherence, motivating honesty parity as a new fairness criterion.
Abstract
Language models exhibit demographic biases in downstream tasks and can be measured for honesty via belief elicitation. Whether these two phenomena interact — with demographic encoding influencing honesty — remains unexplored. We investigate this connection in Gemma 2 2B-IT using a MASK-adapted protocol across 17 scenarios in healthcare, criminal justice, and finance. Linear probes achieve 100% accuracy at predicting user race and gender from residual stream activations at late layers, using only a name as the demographic signal. The resulting demographic direction is correlated with the model's name-conditioned response shift (cosine 0.30 at layer 13, permutation p = 0.015). Ablating this direction during generation reduces overall score variance by 18.5% (bootstrap 95% CI: [2.8%, 32.1%]) and narrows the gender honesty gap by 62% (n = 204 per condition) without degrading coherence. These results suggest that demographic encoding overlaps with honesty-relevant representation subspaces, motivating honesty parity as a new fairness criterion.