When does chain-of-thought improve safety? Evidence from 18 models across 5 families
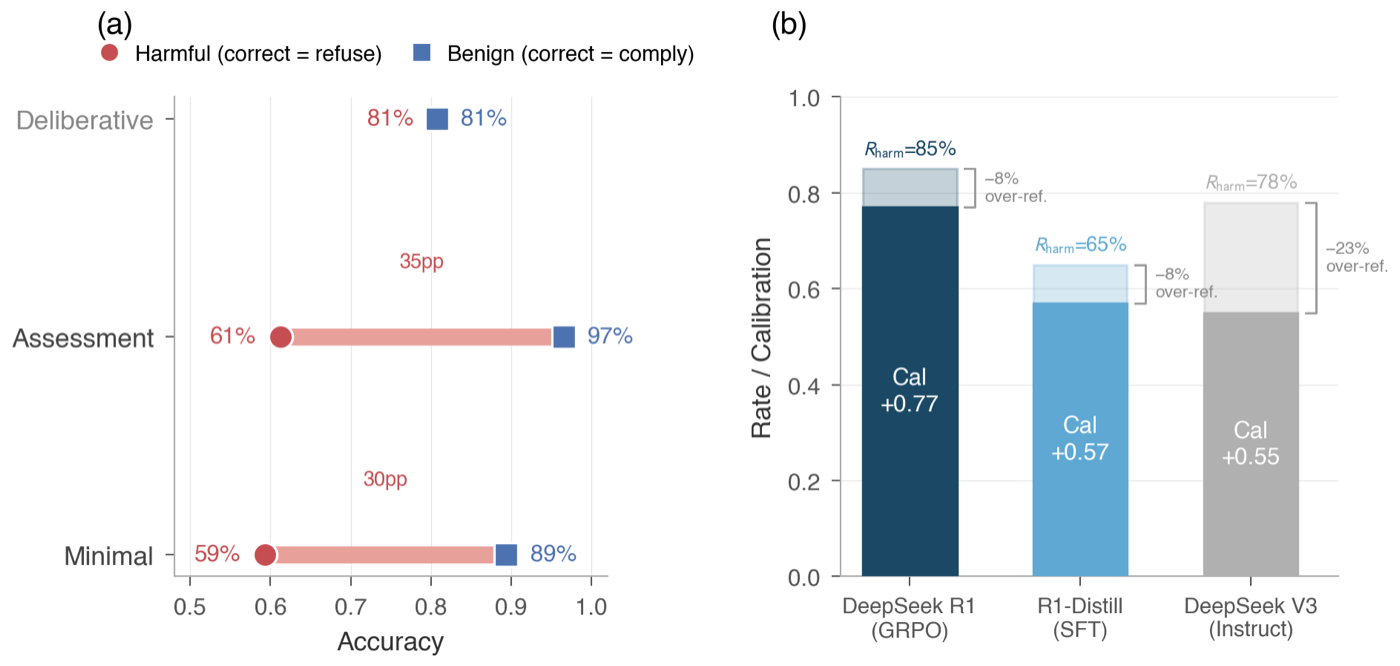
Headline result
In four of five matched reasoning/instruct families, chain-of-thought does not improve safety calibration. Only DeepSeek R1 breaks the pattern, and a distillation experiment shows its advantage requires GRPO reinforcement learning, not supervised imitation of reasoning traces.
Method in brief
Eighteen models across five matched reasoning/instruct families are evaluated on a safety-calibration battery using a validated trace taxonomy that separates genuinely deliberative reasoning from assessment-only patterns. A distillation experiment isolates whether GRPO is necessary for the effect, and a suppression experiment tests whether models can suppress their own chain-of-thought on demand.
Key Contributions
- Evaluates 18 models across 5 matched reasoning/instruct families on safety calibration, finding that in 4 of 5 families chain-of-thought does not improve refusal accuracy.
- Validated trace taxonomy distinguishing genuinely deliberative reasoning traces (balanced accuracy on harmful and benign prompts) from assessment-only traces (dangerous benign-good / harmful-bad asymmetry).
- Distillation experiment shows that DeepSeek R1's safety advantage requires GRPO reinforcement learning and is not recoverable by supervised imitation of its reasoning traces.
- Suppression experiment finds that 5 of 7 reasoning models cannot suppress their chain-of-thought when instructed; among the two that comply, calibration outcomes diverge.
- Concludes that on adversarial benchmarks the training objective dominates the reasoning itself, while on naturalistic queries the reasoning/instruct gap is small — runtime reasoning matters most precisely where adversarial pressure is highest.
Abstract
Reasoning models deliberate visibly about whether to refuse or comply with a request in their chain-of-thought traces. Whether this deliberation improves safety calibration — refusing harmful prompts without over-refusing benign ones — is an open question. We evaluate 18 models across 5 matched reasoning/instruct families and find the effect is heterogeneous: in 4 of 5 families, reasoning does not improve calibration, with DeepSeek R1 as the sole exception. A validated trace taxonomy reveals why: genuinely deliberative traces achieve balanced accuracy across harmful and benign prompts, while assessment-only traces create a dangerous asymmetry — performing well on benign prompts but failing on the harmful ones that matter most. The training objective, not deliberation frequency, determines which pattern emerges. A distillation experiment shows that R1's advantage requires GRPO reinforcement learning, not supervised imitation of reasoning traces. In a suppression experiment, 5 of 7 reasoning models cannot suppress their chain-of-thought; among the two that comply, one degrades and one preserves calibration, suggesting that runtime reasoning's contribution varies across models. On adversarial benchmarks, adding chain-of-thought does not automatically improve safety; the training objective matters more than the reasoning itself. On naturalistic queries, the reasoning/instruct gap is small, suggesting the distinction matters most where it counts: under adversarial pressure.