CAKE: Cloud Architecture Knowledge Evaluation of Large Language Models
Headline result
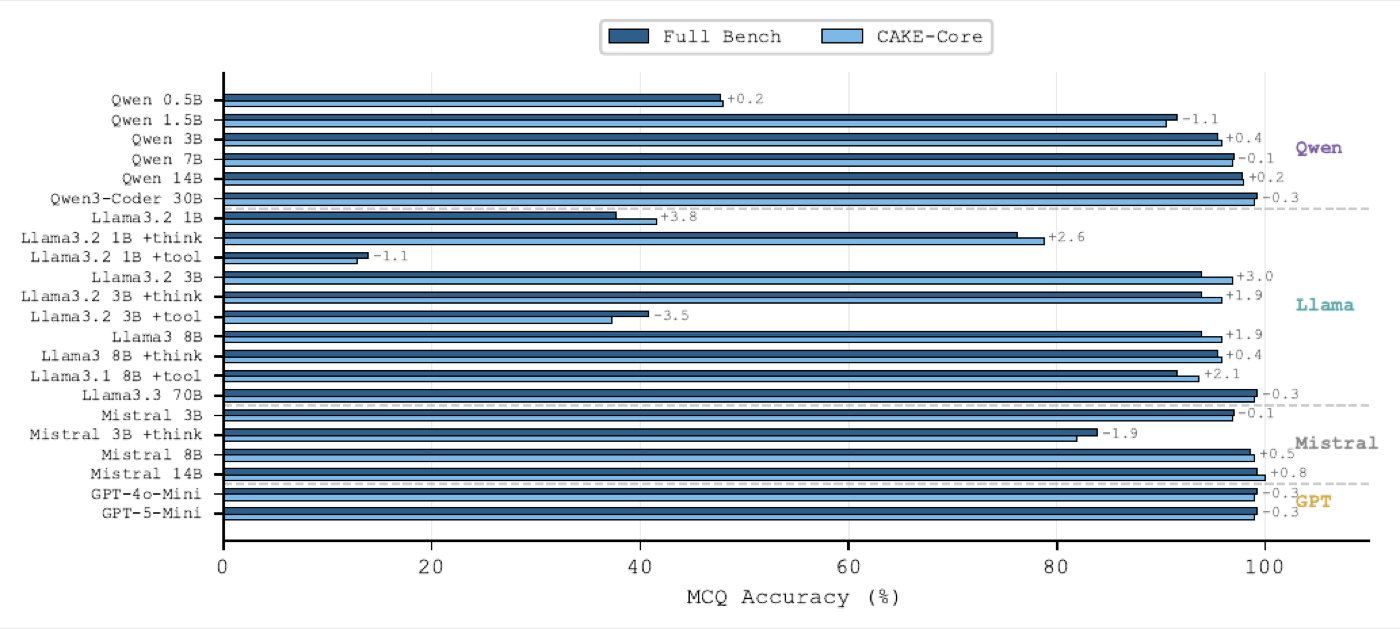
Across 22 model configurations from 0.5B to 70B parameters, multiple-choice accuracy plateaus above 3B (with the best model reaching 99.2%) while free-response scoring continues to differentiate models at every cognitive level. The two formats are not interchangeable and the choice of evaluation format fundamentally shapes how we measure architectural knowledge in LLMs.
Method in brief
CAKE is built from 188 expert-validated questions spanning four cognitive levels of Bloom's revised taxonomy (recall, analyse, design, implement) and five cloud-native topics. Each question is evaluated under both multiple-choice (three-run majority voting) and free-response (LLM-as-a-judge scoring) formats, with reasoning (+think) and tool (+tool) augmentation tested as ablations.
Key Contributions
- Introduces CAKE, a benchmark of 188 expert-validated questions spanning four cognitive levels of Bloom's revised taxonomy and five cloud-native topics.
- Evaluates 22 model configurations (0.5B–70B parameters) from four LLM families, with three-run majority voting for MCQs and LLM-as-a-judge for free-responses.
- Demonstrates that MCQ accuracy plateaus above 3B parameters while free-response scoring continues to differentiate models across cognitive levels.
- Quantifies the effect of reasoning augmentation (+think, beneficial) and tool augmentation (+tool, harmful for small models) on architectural knowledge tasks.
Abstract
In today's software architecture, large language models (LLMs) serve as software architecture co-pilots. However, no benchmark currently exists to evaluate large language models' actual understanding of cloud-native software architecture. For this reason we present a benchmark called CAKE, which consists of 188 expert-validated questions covering four cognitive levels of Bloom's revised taxonomy — recall, analyse, design, and implement — and five cloud-native topics. Evaluation is conducted on 22 model configurations (0.5B–70B parameters) across four LLM families, using three-run majority voting for multiple-choice questions (MCQs) and LLM-as-a-judge scoring for free-responses (FR). Based on this evaluation, four notable findings were identified. First, MCQ accuracy plateaus above 3B parameters, with the best model reaching 99.2%. Second, free-response scores scale steadily across all cognitive levels. Third, the two formats capture different facets of knowledge, as MCQ accuracy approaches a ceiling while free-responses continue to differentiate models. Finally, reasoning augmentation (+think) improves free-response quality, while tool augmentation (+tool) degrades performance for small models. These results suggest that the evaluation format fundamentally shapes how we measure architectural knowledge in LLMs.