AutoRed: Measuring the Elicitation Gap via Automated Red-Blue Optimization
TL;DR
Automated red-team and blue-monitor optimisation partially closes the elicitation gap, but the optimised strategies are brittle to distribution shift: a simple threshold baseline beats them on held-out tasks. Elicitation-gap measurements without held-out evaluation across attack distributions are unreliable.
Headline result
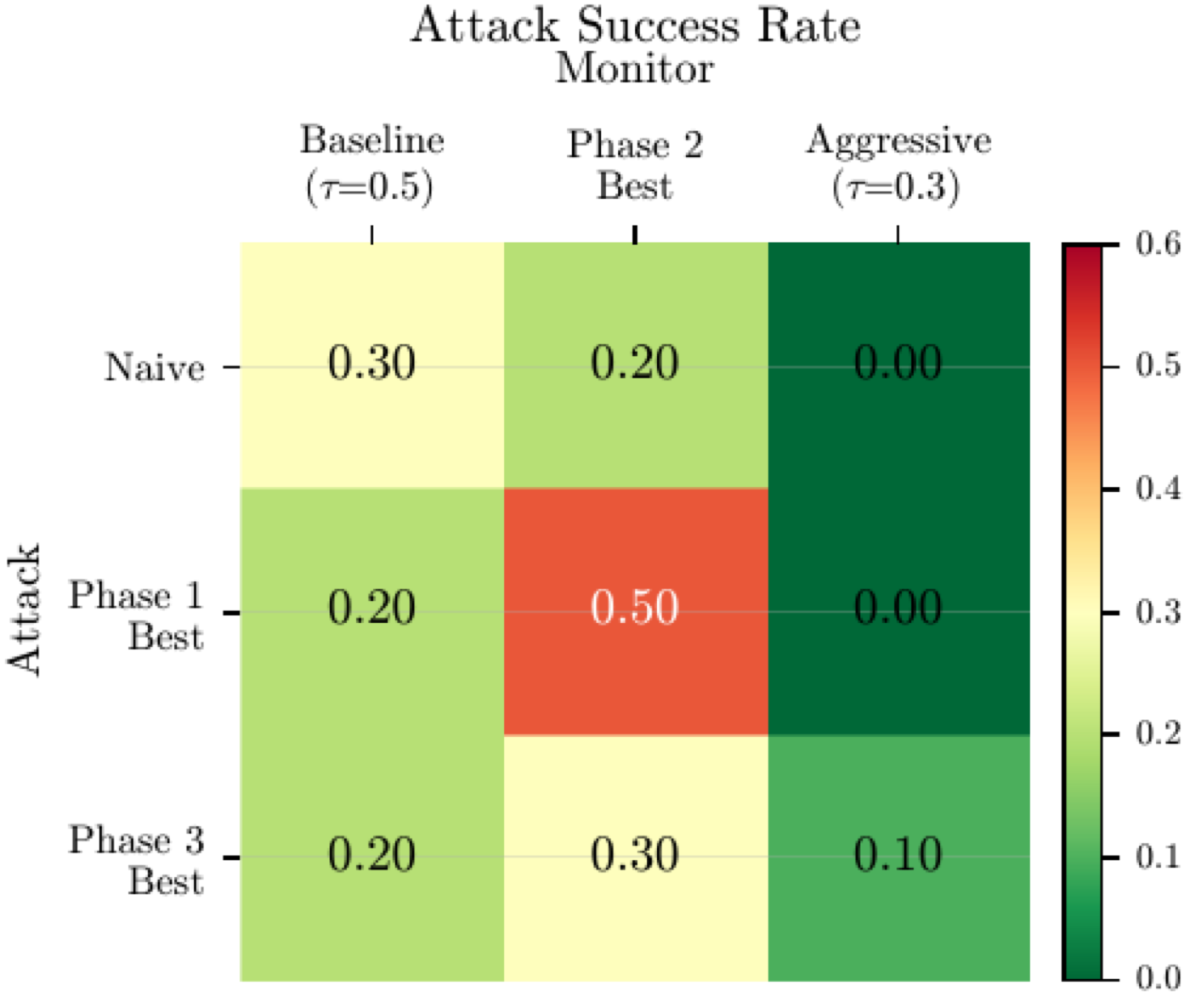
The best optimised monitor achieves 90% safety during training but averages just 47% on held-out tasks with a different attack mechanism, while a simple threshold baseline maintains 100% with zero variance. On held-out tasks the baseline reaches AUROC = 0.85 while the optimised monitor sits at 0.50, that is, chance.
Method in brief
AutoRed is a five-phase framework where a reasoning model acts as meta-optimizer for both red-team attack optimisation and blue-team monitor optimisation in a code backdoor detection setting adapted from the AI Control framework. The phases run baselines, independent red and blue optimisation, co-evolution, and a transfer test on held-out tasks, with a 3 × 3 transfer matrix isolating the contribution of optimisation on each side.
Key Contributions
- AutoRed: a five-phase framework that automates both attack and defence optimisation using a reasoning model as meta-optimiser, enabling systematic elicitation-gap measurement.
- Empirical demonstration that automated optimisation partially closes the gap (red: 0% → 30%; blue: 90% safety at 90% usefulness), with oscillatory co-evolutionary dynamics where neither side converges.
- Cautionary central finding: optimised strategies overfit to their training opponents. The best optimised monitor drops from 90% training safety to 47% on held-out tasks while a simple threshold baseline holds at 100%.
- Methodological recommendation that any automated red-teaming pipeline reporting elicitation-gap measurements must include held-out evaluation across attack distributions, with pattern-agnostic baselines accompanying optimised strategies as a robustness check.
Abstract
Evaluating AI safety requires understanding the elicitation gap: the difference between a system's safety under naive evaluation and its safety under best-effort adversarial testing. Manual red teaming is expensive and does not scale. We introduce AutoRed, a five-phase framework that automates both red team attack optimization and blue team monitor optimization using a reasoning model as meta-optimizer. In a code backdoor detection setting adapted from the AI Control framework, AutoRed iteratively generates, evaluates, and improves strategies on both sides, then tests whether the improvements generalize. Automated optimization partially closes the elicitation gap: red attacks improve and blue monitors adapt. Co-evolutionary dynamics are oscillatory, with neither side converging. The central finding is cautionary: optimized strategies are brittle to distribution shift. The best optimized monitor drops from 90% safety during training to 47% on held-out tasks with a different attack mechanism, while a simple threshold baseline maintains 100%. Elicitation gap measurements without held-out evaluation across attack distributions are unreliable.