A Reference Architecture for Agentic Hybrid Retrieval in Dataset Search
Headline result
An offline metadata augmentation step (where an LLM generates pseudo-queries for each dataset record) closes the vocabulary gap between user intent and provider-authored metadata, with seven system variants in the evaluation framework isolating the contribution of each architectural decision.
Method in brief
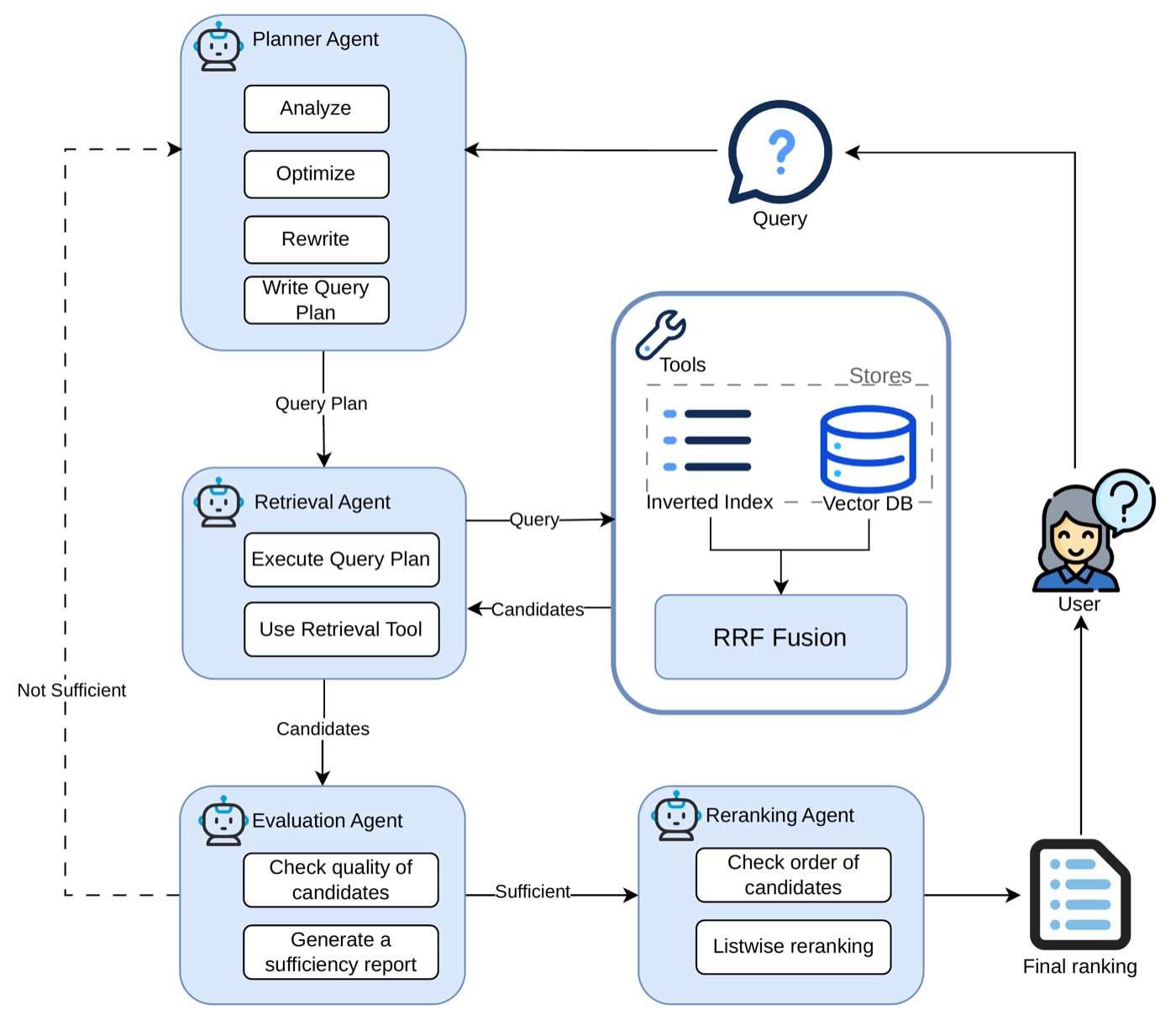
BM25 lexical search and dense-embedding retrieval are combined via reciprocal rank fusion, orchestrated by an LLM agent that plans queries, evaluates result sufficiency, and reranks. Two architectural styles are compared: a single ReAct agent and a multi-agent horizontal architecture with Feedback Control, with explicit governance tactics bounding the non-deterministic LLM components.
Key Contributions
- Repositions ad hoc dataset search as a software-architecture problem and proposes a bounded, auditable reference architecture for agentic hybrid retrieval.
- Combines BM25 lexical search with dense-embedding retrieval via reciprocal rank fusion, orchestrated by an LLM controller that plans, evaluates, and reranks.
- Introduces an offline metadata augmentation step where an LLM generates pseudo-queries for each dataset record to reduce vocabulary mismatch with user intent.
- Compares a single-ReAct-agent style against a multi-agent horizontal architecture with Feedback Control, with explicit quality-attribute tradeoffs and an evaluation framework of seven system variants.
Abstract
Ad hoc dataset search requires matching underspecified natural-language queries against sparse, heterogeneous metadata records, a task where typical lexical or dense retrieval alone falls short. We reposition dataset search as a software-architecture problem and propose a bounded, auditable reference architecture for agentic hybrid retrieval that combines BM25 lexical search with dense-embedding retrieval via reciprocal rank fusion (RRF), orchestrated by a large language model (LLM) agent that repeatedly plans queries, evaluates the sufficiency of results, and reranks candidates. To reduce the vocabulary mismatch between user intent and provider-authored metadata, we introduce an offline metadata augmentation step in which an LLM generates pseudo-queries for each dataset record, augmenting both retrieval indexes before query time. Two architectural styles are examined: a single ReAct agent and a multi-agent horizontal architecture with Feedback Control. Their quality-attribute tradeoffs are analysed with respect to modifiability, observability, performance, and governance. An evaluation framework comprising seven system variants is defined to isolate the contribution of each architectural decision. The architecture is presented as an extensible reference design for the software-architecture community, incorporating explicit governance tactics to bound and audit non-deterministic LLM components.